1. 基本数据类型 1.1 整型 整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 对应的无符号整型:uint8、uint16、uint32、uint64。其中,uint8就是我们熟知的byte型。
类型 描述
uint8
无符号 8位整型 (0 到 255)
uint16
无符号 16位整型 (0 到 65535)
uint32
无符号 32位整型 (0 到 4294967295)
uint64
无符号 64位整型 (0 到 18446744073709551615)
int8
有符号 8位整型 (-128 到 127)
int16
有符号 16位整型 (-32768 到 32767)
int32
有符号 32位整型 (-2147483648 到 2147483647)
int64
有符号 64位整型 (-9223372036854775808 到 9223372036854775807)
uint
32位操作系统上就是uint32,64位操作系统上就是uint64
int
32位操作系统上就是int32,64位操作系统上就是int64
uintptr
无符号整型,用于存放一个指针
1 2 3 4 5 6 7 8 9 10 11 12 var a int = 10 "%d \n" , a) "%b \n" , a) var b int = 077 "%o \n" , b) var c int = 0xff "%x \n" , c) "%X \n" , c)
1.2 浮点类型 Go语言支持两种浮点型数:float32和float64
1 2 fmt.Printf("%f\n" , math.Pi) "%.2f\n" , math.Pi)
1.3 bool类型 Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
注意:
布尔类型变量的默认值为false。
Go 语言中不允许将整型强制转换为布尔型.
布尔型无法参与数值运算,也无法与其他类型进行转换。
2. 类型定义与类型别名 2.1 自定义类型 在Go语言中有一些基本的数据类型,如string、整型、浮点型、布尔等数据类型, Go语言中可以使用type关键字来定义自定义类型。
自定义类型是定义了一个全新的类型。我们可以基于内置的基本类型定义,也可以通过struct定义。例如:
通过type关键字的定义,MyInt就是一种新的类型,它具有int的特性
2.2 类型别名 型别名规定:TypeAlias只是Type的别名,本质上TypeAlias与Type是同一个类型。就像一个孩子小时候有小名、乳名,上学后用学名,英语老师又会给他起英文名,但这些名字都指的是他本人。
我们之前见过的rune和byte就是类型别名,他们的定义如下:
1 2 type byte = uint8 type rune = int32
2.3 区别 类型别名与类型定义表面上看只有一个等号的差异,但他们之间存在区别。
1 2 3 4 5 6 7 8 9 10 11 12 13 type NewInt int type MyInt = int func main () var a NewIntvar b MyInt"type of a:%T" , a) "type of b:%T" , b)
结果显示a的类型是main.NewInt,表示main包下定义的NewInt类型。b的类型是int。MyInt类型只会在代码中存在,编译完成时并不会有MyInt类型
3 字符串 3.1 常用方法
方法 介绍
len(str)
求长度
+或fmt.Sprintf或 strings.Builder
拼接字符串
strings.Split
分割
strings.contains
判断是否包含
strings.HasPrefix,strings.HasSuffix
前缀/后缀判断
strings.Index(),strings.LastIndex()
子串出现的位置
strings.Join(a[]string, sep string)
join操作
3.2 byte和rune string中每一个元素叫字符,字符有两种:
byte:1个字节,代表ASCII码的一个字符
rune:4个字节,代表一个UTF-8字符,一个汉字可用一个rune表示
string底层就是byte数组,string的长度就是该byte数组的长度,UTF-8编码下一个汉字占3个byte,即一个汉字占三个长度
string是常量,不能修改其中的字符,可以将string转为[]byte或者rune类型在修改其值
1 2 3 4 5 6 7 8 9 10 11 12 func changeString () "big" byte (s1)0 ] = 'p' string (byteS1))"白萝卜" rune (s2)0 ] = '红' string (runeS2))
4 类型转换 Go语言中只有强制类型转换,没有隐式类型转换,如下:
byte和int可以相互转换
float与int可以相互转换,小数位会丢失
bool和int不能互相转换
string可以转换为[]byte或者[]rune类型,byte或rune可以转为string类型
低精度向高精度转换没有类型,高精度向低精度转换会丢失位数
无符号向有符号转换,最高位是符号位
5. 数组 数组是一块连续的内存空间,在声明的时候必须指定长度,且长度不能改变。所以数组在声明的时候就可以把内存空间分配好,并且附上默认值,即完成数组的初始化。
5.1 数组定义 1 2 3 4 5 var 数组名 [元素数量]Tvar a [3 ]int var b [4 ]int
5.2 数组的初始化 1 2 3 4 var testArray [3 ]int var numArray = [3 ]int {1 , 2 } var cityArray = [3 ]string {"北京" , "上海" , "深圳" }
1 2 3 4 5 6 7 8 9 var testArray [3 ]int var numArray = [...]int {1 , 2 }var cityArray = [...]string {"北京" , "上海" , "深圳" }"type of numArray:%T\n" , numArray) "type of cityArray:%T\n" , cityArray)
1 2 3 4 int {1 : 1 , 3 : 5 }"type of a:%T\n" , a)
5.3 数组的遍历 1 2 3 4 5 6 7 8 9 10 11 func main () var a = [...]string {"北京" , "上海" , "深圳" }for i := 0 ; i < len (a); i++ {for index, value := range a {
5.4 数值是值类型 数组是值类型,赋值和传参会复制整个数组。因此改变副本的值,不会改变本身的值。建议传指针。[n]*T表示指针数组,*[n]T表示数组指针。
1 2 3 4 5 6 7 8 9 func modifyArray (x [3]int ) 0 ] = 100 func main () 3 ]int {10 , 20 , 30 }
6. 切片 切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。
6.1 切片的定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 func main () var a []string var b = []int {} var c = []bool {false , true } var d = []bool {false , true } nil ) nil ) nil )
切片拥有自己的长度和容量,我们可以通过使用内置的len()函数求长度,使用内置的cap()函数求切片的容量。
切片的底层就是一个数组,所以我们可以基于数组通过切片表达式得到切片。 切片表达式中的low和high表示一个索引范围(左包含,右不包含),也就是下面代码中从数组a中选出1<=索引值<4的元素组成切片s,得到的切片长度=high-low,容量等于得到的切片的底层数组的容量,对切片再执行切片表达式时(切片再切片),high的上限边界是切片的容量cap(a),而不是长度。
1 2 3 4 5 6 func main () 5 ]int {1 , 2 , 3 , 4 , 5 }1 :3 ] "s:%v len(s):%v cap(s):%v" , s, len (s), cap (s))
6.2 make构造切片 如果需要动态的创建一个切片,我们就需要使用内置的make()函数,格式如下:
1 2 3 4 5 6 7 8 make ([]T, size, cap ) func main () make ([]int , 2 , 10 )len (a)) cap (a))
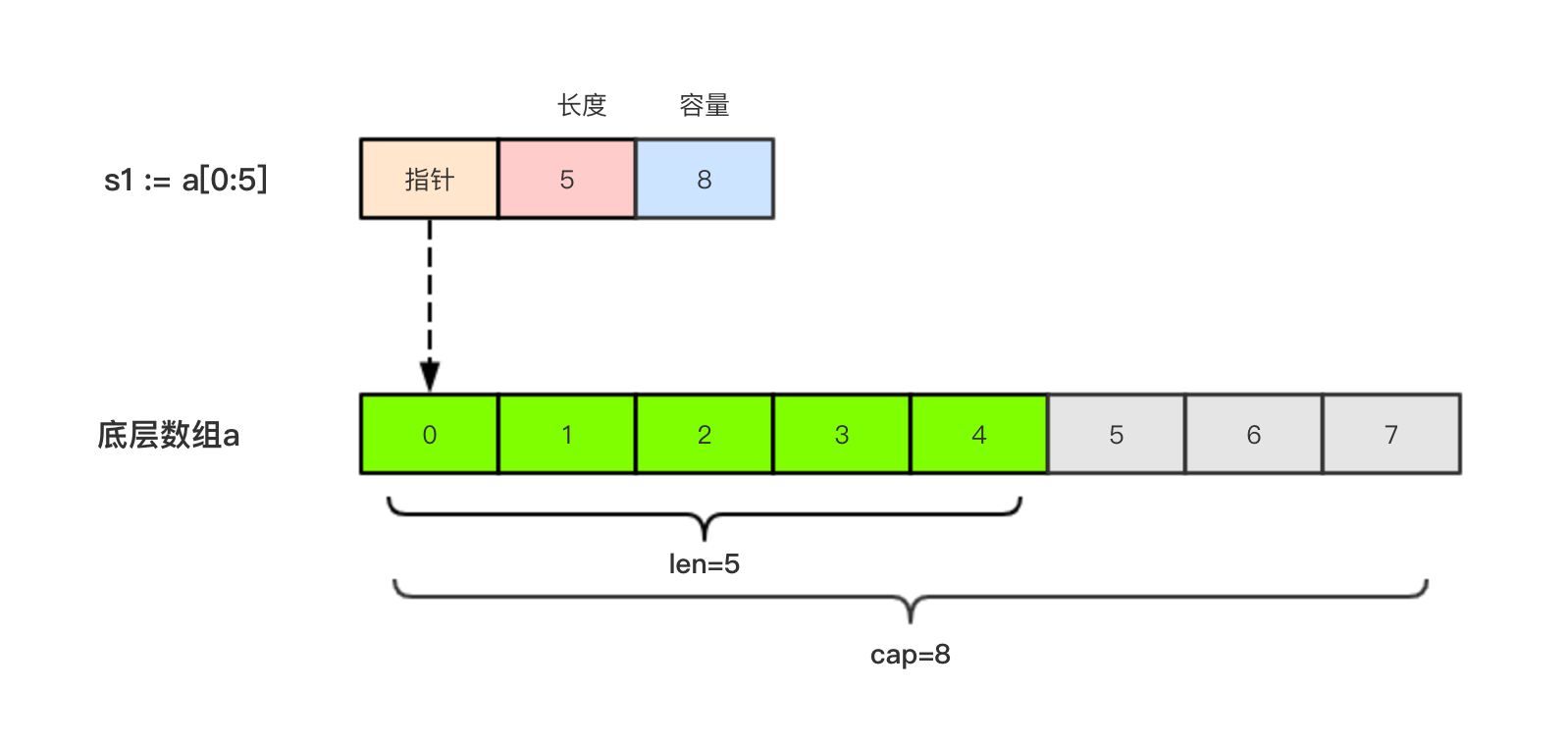
6.3 切片的本质 切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)。举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图如下。
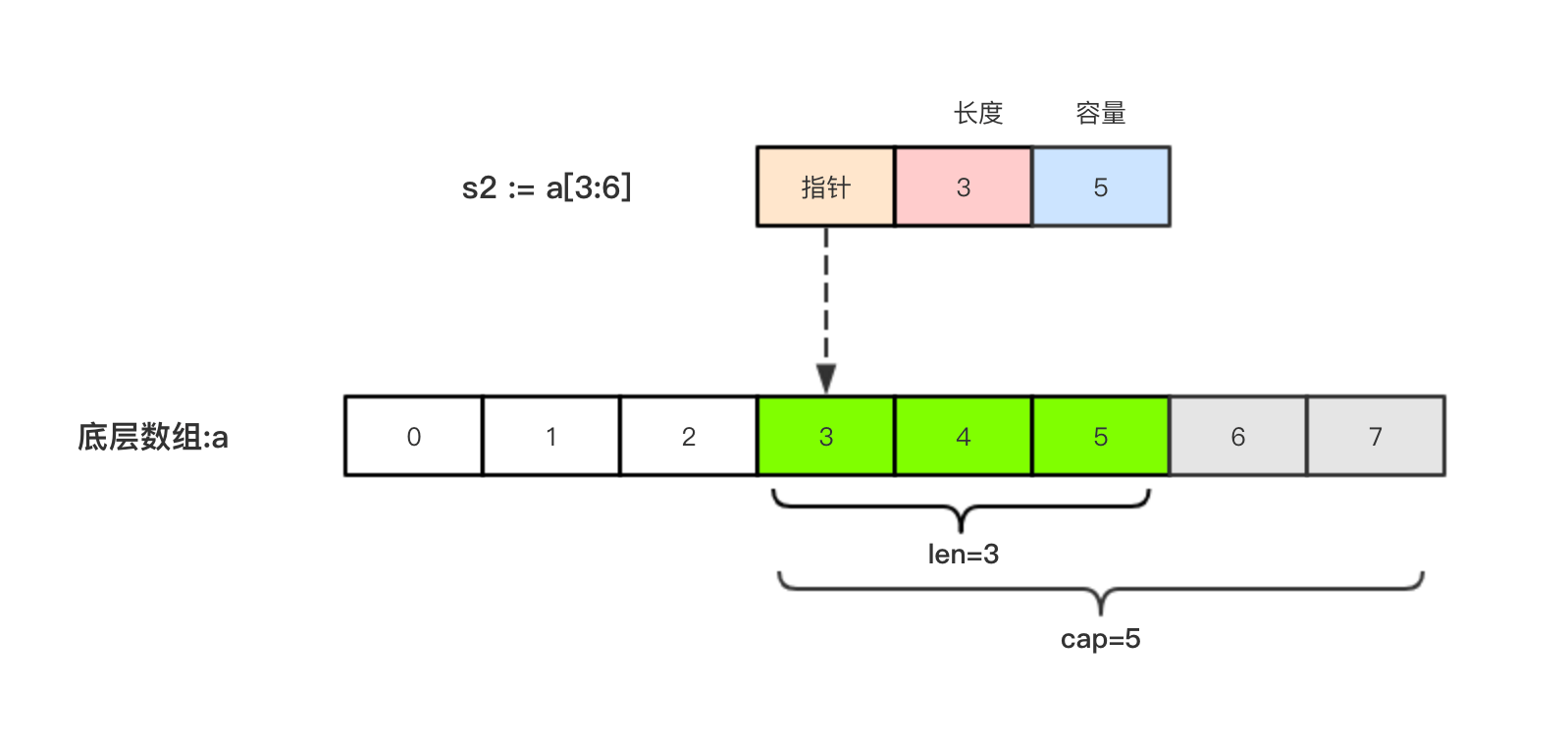
切片s2 := a[3:6],相应示意图如下:
6.4 切片拷贝复制 下面的代码中演示了拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,这点需要特别注意。当需要修改元素时,又不想修改原切片本身,可以使用copy函数复制一个新的切片进行操作。
1 2 3 4 5 6 7 func main () make ([]int , 3 ) 0 ] = 10
1 2 3 4 int {1 , 2 , 3 , 4 , 5 }make ([]int , 5 , 5 )copy (c, a)
6.5 切片添加 每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func main () var numSlice []int for i := 0 ; i < 10 ; i++ {append (numSlice, i)"%v len:%d cap:%d ptr:%p " , numSlice, len (numSlice), cap (numSlice), numSlice)0 ] len :1 cap :1 ptr:0xc0000a8000 0 1 ] len :2 cap :2 ptr:0xc0000a8040 0 1 2 ] len :3 cap :4 ptr:0xc0000b2020 0 1 2 3 ] len :4 cap :4 ptr:0xc0000b2020 0 1 2 3 4 ] len :5 cap :8 ptr:0xc0000b6000 0 1 2 3 4 5 ] len :6 cap :8 ptr:0xc0000b6000 0 1 2 3 4 5 6 ] len :7 cap :8 ptr:0xc0000b6000 0 1 2 3 4 5 6 7 ] len :8 cap :8 ptr:0xc0000b6000 0 1 2 3 4 5 6 7 8 ] len :9 cap :16 ptr:0xc0000b8000 0 1 2 3 4 5 6 7 8 9 ] len :10 cap :16 ptr:0xc0000b8000
1 2 3 4 5 6 7 8 9 10 var citySlice []string append (citySlice, "北京" )append (citySlice, "上海" , "广州" , "深圳" )string {"成都" , "重庆" }append (citySlice, a...)
6.6 切片扩容策略 可以通过查看$GOROOT/src/runtime/slice.go源码,其中扩容相关代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 newcap := old.cap if cap > doublecap {cap else {if old.len < 1024 {else {for 0 < newcap && newcap < cap {4 if newcap <= 0 {cap
从上面的代码可以看出以下内容:
首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)。
如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样。
6.7 切片元素删除 Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素。 代码如下:
1 2 3 4 5 6 7 8 func main () int {30 , 31 , 32 , 33 , 34 , 35 , 36 , 37 }append (a[:2 ], a[3 :]...)
7. map Go语言中提供的映射关系容器为map,其内部使用散列表(hash)实现。map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。
1 2 3 4 // 定义语法
map类型的变量默认初始值为nil,需要使用make()函数来分配内存。
7.1 基本使用 1 2 3 4 5 6 7 8 9 func main () make (map [string ]int , 8 )"张三" ] = 90 "小明" ] = 100 "小明" ])"type of a:%T\n" , scoreMap)
1 2 3 4 5 6 7 8 func main () map [string ]string {"username" : "沙河小王子" ,"password" : "123456" ,
7.2 判断某个键是否存在 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 map [key]func main () make (map [string ]int )"张三" ] = 90 "小明" ] = 100 "张三" ]if ok {else {"查无此人" )
7.3 map的遍历 1 2 3 4 5 6 7 8 9 10 func main () make (map [string ]int )"张三" ] = 90 "小明" ] = 100 "娜扎" ] = 60 for k, v := range scoreMap {
1 2 3 4 5 6 7 8 9 10 func main () make (map [string ]int )"张三" ] = 90 "小明" ] = 100 "娜扎" ] = 60 for k := range scoreMap {
遍历map时的元素顺序与添加键值对的顺序无关。
7.4 map键值删除 1 2 3 4 5 6 7 8 9 10 11 func main () make (map [string ]int )"张三" ] = 90 "小明" ] = 100 "娜扎" ] = 60 delete (scoreMap, "小明" ). for k,v := range scoreMap{
7.5 元素为map类型的切片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func main () var mapSlice = make ([]map [string ]string , 3 )for index, value := range mapSlice {"index:%d value:%v " , index, value)"after init" )0 ] = make (map [string ]string , 10 )0 ]["name" ] = "小王子" 0 ]["password" ] = "123456" 0 ]["address" ] = "沙河" for index, value := range mapSlice {"index:%d value:%v " , index, value)
7.6 值为切片类型的map 1 2 3 4 5 6 7 8 9 10 11 12 13 func main () var sliceMap = make (map [string ][]string , 3 )"after init" )"中国" if !ok {make ([]string , 0 , 2 )append (value, "北京" , "上海" )
8. 指针 任何程序数据载入内存后,在内存都有他们的地址,这就是指针。而为了保存一个数据在内存中的地址,我们就需要指针变量。比如,“永远不要高估自己”这句话是我的座右铭,我想把它写入程序中,程序一启动这句话是要加载到内存(假设内存地址0x123456),我在程序中把这段话赋值给变量A,把内存地址赋值给变量B。这时候变量B就是一个指针变量。通过变量A和变量B都能找到我的座右铭。
Go语言中的指针不能进行偏移和运算,因此Go语言中的指针操作非常简单,我们只需要记住两个符号:&(取地址)和*(根据地址取值)。
8.1 指针地址 每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用&字符放在变量前面对变量进行“取地址”操作。
1 2 3 ptr := &v // v的类型为T
8.2 指针取值 在对普通变量使用&操作符取地址后会获得这个变量的指针,然后可以对指针使用*操作,也就是指针取值,代码如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func main () 10 "type of b:%T" , b)"type of c:%T" , c)"value of c:%v" , c)
取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
对变量进行取地址(&)操作,可以获得这个变量的指针变量。
指针变量的值是指针地址。
对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
8.3 new new是一个内置的函数,它的函数签名如下:
使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。举个例子:
1 2 3 4 5 6 7 8 func main () new (int )new (bool )"%T\n" , a) "%T\n" , b)
如下示例代码中var a *int只是声明了一个指针变量a但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的new函数对a进行初始化之后就可以正常对其赋值了:
1 2 3 4 5 6 func main () var a *int new (int )10
8.4 make make也是用于内存分配的,区别于new,它只用于slice、map以及channel的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。make函数的函数签名如下:
1 func make (t Type, size ...IntegerType)
make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作。
如下的示例中var b map[string]int只是声明变量b是一个map类型的变量,需要像下面的示例代码一样使用make函数进行初始化操作之后,才能对其进行键值对赋值:
1 2 3 4 5 6 func main () var b map [string ]int make (map [string ]int , 10 )"沙河娜扎" ] = 100
8.5 new与make的区别
二者都是用来做内存分配的。
make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
8.6 引用类型
slice、map、channel是go语言里面的三种引用类型,都可以通过make函数来初始化申请内存分配
因为他们都包含一个指向底层数据结构的指针,所以称之为引用类型。
引用类型未初始化时都是nil,可以对他执行len函数,返回0值