ClickHouse数据库
1 ClickHouse简介
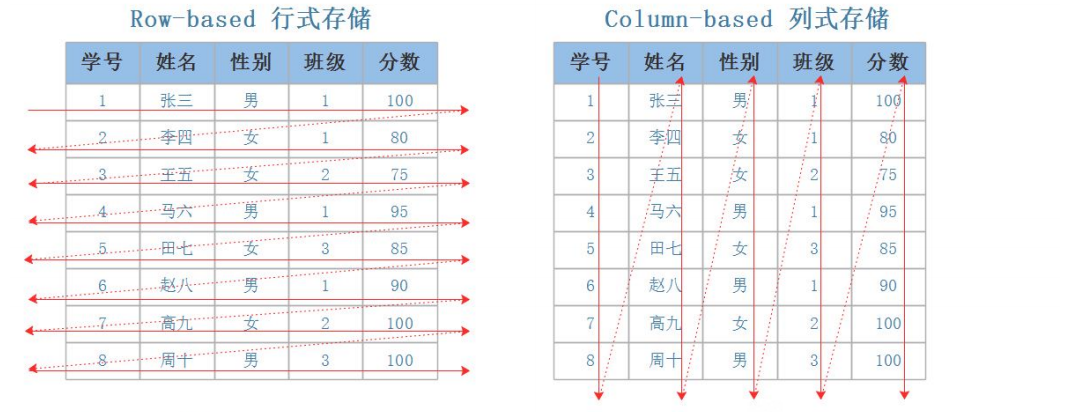
1.1 行式数据库与列式数据库
clickHouse是一个用于联机分析的列式数据库管理系统,列式数据库通常都是事务较少,数据量较大的清理。多用于日志存储、数据分析等。官网介绍
1.2 良好的数据压缩比
clickhouse 使用 lz4 压缩数据,在保证数据读写性能的前提下、它的数据压缩比最高(占用空间最少),而且查询性能非常快,压缩比基本在25左右。
1 | |
1.3 特性
- 列式数据库
- 良好的数据压缩比
- 对存储无依赖,且即使在 HDD 也能实现良好的性能,但推荐 SSD
- 合理利用多核心 CPU 提高性能 - 单进程多线程的
- 支持 SQL 语句,https://clickhouse.com/docs/zh/sql-reference
- 向量引擎:为了高效的使用 CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用 CPU。
- 索引:按照主键对数据进行排序,这将帮助 ClickHouse 在几十毫秒以内完成对数据特定值或范围的查找。
- 适合在线查询:在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
- 支持近似计算(内置近似计算函数),在牺牲数据精准性的前提下提高性能
- 支持自适应连接算法,clickHouse 支持自定义 JOIN 多个表,它更倾向于散列连接算法,
- 如果有多个大表 ,则使用合并 - 连接算法 ,https://clickhouse.com/docs/zh/sql-reference/statements/select/join
- 支持数据复制和数据完整性
- 支持角色访问控制
1.4 使用场景
- 绝大多数客户端请求都是用于读请求
- 数据需要以大批次(大于 1000 行)进行更新,而不是单行更新;或者根本没有更新操作
- 数据只是添加到数据库,没有必要修改
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列(一次读取角度的数据)
- 表很“宽”,即表中包含大量的列,也就是表的数据量比较大
- 查询频率相对较低的非高并发场景(通常每台 CH 服务器每秒查询数百次)
- 对于简单查询,允许大约 50 毫秒的延迟
- 列的值是比较小的数值和短字符串
- 在处理单个客户端查询时需要高吞吐量(每台服务器每秒高达数十亿行)
- 不需要事务的场景(不支持事务)
- 数据一致性要求较低(副本同步有延迟)
- 每次查询中只会查询一个大表,除了一个大表,其余都是小表(较少跨表查询)
- 查询结果显著小于数据源,即数据有过滤或聚合、返回结果不超过单个服务器内存大小。
1.5 缺点
- 没有完整的事务支持。
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据。
- 稀疏索引导致 ClickHouse 不擅长细粒度或者 key-value 类型数据的查询需求。稀疏索引是一种优化空间使用的索引方式,它只为非空值建立索引。如果表中的某些字段有很多空值,使用稀疏索引可以节省很多空间。
- 不擅长 join 操作,且语法特殊
- 由于采用并行处理机制,即使一个客户端(的大量)查询也会使用较多的 CPU 资源,所以不支持高并发。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!